[This article was migrated to the author’s GitHub Pages site here in July 2025]
This article is the first in a sequence of three dealing with a very general class of problems in SQL, and exploring various techniques to find efficient solutions. In this first article, the problem is outlined and is divided into two subproblems, of which the first is solved here in several variant SQL statements with performance analysis. The second article, Holographic Set Matching in SQL, takes the most efficient method and applies two new techniques to further improve performance. The third article, Master-Detail Transaction Reconciliation in SQL (MDTM3), adds a sequence of subquery factors to the best solution for the first subproblem to achieve an efficient solution to the overall problem within a single SQL statement.
The General Problem
We consider a transaction with a two-level structure consisting of a header (or master) and lines (or details) linked to the header, and the problem is to pair off transactions by matching, or contra-matching, subsets of the fields at both header and line level. This kind of problem can arise in the context of reconciliation of debit and credit transactions where both transactions are in the same system but are entered separately by two different groups and have no explicit linkage. Typically, in order for the transactions to match at header level, several fields such as transaction class have to be equal, while others such as credit and debit amounts have to be inverse, while others again such as unique identifiers will not match. At the line level, the same applies and matched lines also need to pair off against each other for the transaction to be considered a match. The first part of the problem is to identify all matching (or contra-matching) pairs, and this article will focus on that, while the second (and optional) part, that of pairing off, will be the subject of a later article.
To see why performance might be an important issue for this type of problem, consider the number of possible comparisons for an example with 10,000 headers each having 100 lines. In this case there would be 100,000,000 pairs of transactions, counting both ways, and 50,000,000 counting one way. A similar calculation gives 10,000 (not 5,000!) line comparisons per header-pair, and hence 500,000,000,000 line comparisons in total. The key of course is to minimise the number of comparisons made explicitly.
We will solve the problem through a single SQL query which will be developed through several versions, using a test example problem based on Oracle standard tables. The queries will be tested using my own SQL benchmarking framework, mentioned in earlier articles, and performance characteristics analysed. This will illustrate some performance aspects of the use of subquery factors and temporary tables, among other things.
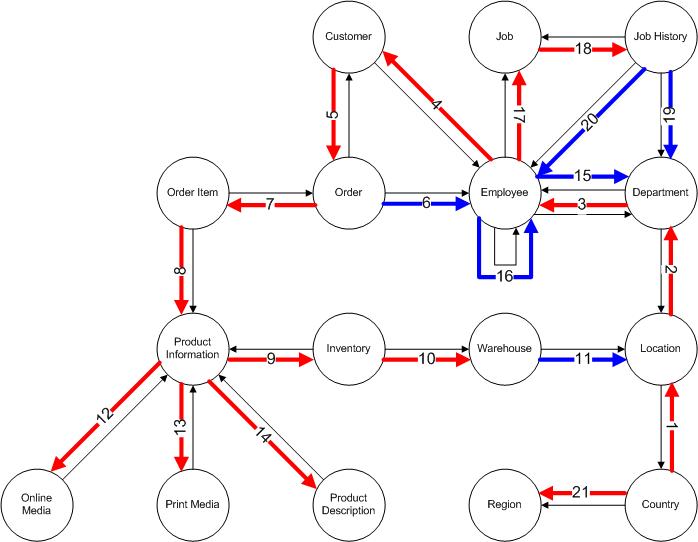
Matching and Contra-Matching Sets

In the ERD above, each transaction falls into a logical Match Status Set, where the sets are of four distinct types:
- Unmatched – a single set for transactions having no matching or contra-matching transaction
- Matched – a set for each group of mutually matching transactions
- Contra-Matched A -?a set for each group of transactions that all contra-match to a corresponding B-set
- Contra-Matched B -?a set for each group of transactions that all contra-match to a corresponding A-set
We may define our problem without contra-matching fields, in which case only the first two types of set will be present; we may also have the case where only contra-matching is possible (likely the most common); and a special case may arise where both matching and contra-matching fields are present but where all contra-matching fields may have self-inverse values (for example amounts of zero) and those records having only self-inverse values might be best regarded as falling into one of the first two types of set.
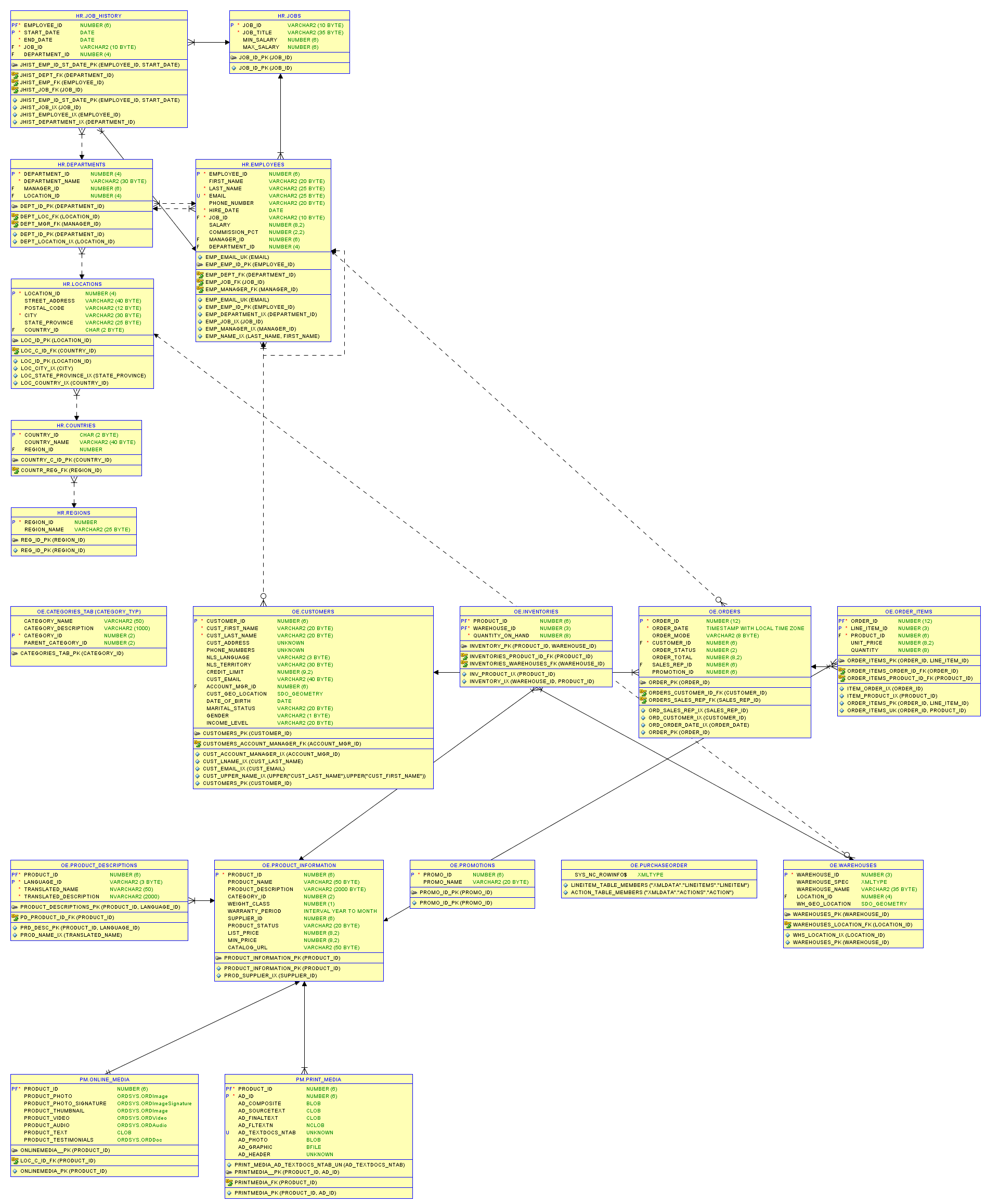
The Sample Problem – Tables and Foreign Key Constraints
We will use two of the Oracle database system views as the basis for our sample problem. The master entity will be the Oracle table defined in the view all_tables, and the detail entity will be the foreign key constraint contained as a subentity in the view all_constraints. The views themselves are very complicated and it is better for our purposes to copy their records into new tables, and for performance testing we’ll copy them multiple times according to the value of a dimensional parameter, using the parameter as a suffix on the owner and table name fields. The sample problem will involve matching only, and tables are defined to match if they have the same set of foreign key references, where the references are defined by the referenced owners and constraint names. As tables without foreign keys all match trivially, we’ll filter these out in the queries.
The table and constraint entities can be represented by the following ERD:

The tables are, with * marking primary keys:
tab_cp
- owner*
- table_name*
- description
con_cp
- owner*
- constraint_name*
- table_name
- constraint_type
- r_owner
- r_constraint_name
- description
Indexes are defined on the two foreign keys on con_cp:
con_tab_fk_N1
con_con_fk_N2
- r_owner
- r_constraint_name
The embedded Excel file below gives the solution for my 11g XE database, for the first problem, of identifying all matches.
Solution Methods
This problem might be considered to divide into two subproblems. The first is to identify all the matching pairs, while the second is to take those matching pairs and eliminate duplicate instances, so that each master record matches against at most one other record. This may reduce the number of master records that have matches; for example, if a matching set has three master records, then only two of them will be matched, against each other, in the final solution. We will consider the first subproblem in this article and the second in a later article.
To find the solution to the first subproblem in SQL, the obvious approach is simply to join the master table to itself to form the set of possible matching pairs, then to apply criteria to filter out any pairs that don’t match. Obviously, we can immediately apply a constraint to avoid selecting the same pair twice by requiring that the rowid of the first record be higher than that of the second. This will halve the number of pairs considered, reducing the initial set of pairs from n! to n!/2 (where ! denotes the mathematical factorial function), and also halving the number after applying any other conditions.
Matching Detail Sets with MINUS Operator
The master-level criteria may be easy enough to apply, using conditions in the join clause, but the detail criteria are more difficult because we have to match two sets of records for any given pair of master records. This leads us to think of Oracle’s set operators, specifically the MINUS operator that subtracts one set from another. Consider the matching pair on line 4028 of the Excel file above, with he solution for our example problem. This shows a match between the two tables OEHR_EMPLOYEES and OEHR_JOB_HISTORY in the TWODAYPLUS_0 schema, each of which has three foreign keys. The three constraints on each of these tables reference the same keys in the same schema, namely DEPT_ID_PK, JOB_ID_PK, EMP_EMP_ID_PK. The following query returns no records:
SELECT r_owner,
r_constraint_name
FROM con_cp
WHERE constraint_type = 'R'
AND table_name = 'OEHR_EMPLOYEES'
AND owner = 'TWODAYPLUS_0'
MINUS
SELECT r_owner,
r_constraint_name
FROM con_cp
WHERE constraint_type = 'R'
AND table_name = 'OEHR_JOB_HISTORY'
AND owner = 'TWODAYPLUS_0'
Perhaps then the detail set matching could be effected by a NOT EXISTS clause on the above query with the hard-coded owner and table_name replaced by correlation columns from the main query? There are two problems with this arising from the way Oracle’s set operators work. First, if there were any extra foreign keys in the second table the query would still return no records, as it returns only records that are in the first query section and not in the second, thus showing a false match. Second, Oracle views a set in this context as being the set of distinct records, so if some records are duplicated in either table, but differently from the other one then again a false match is shown. These two tables also exist in Oracle’s HR demo schema, without the OEHR_ prefix. In order to show the problem I added an extra field in each table with a foreign key matching one already present, as follows:
- EMPLOYEES.REL_EMP_ID -> EMP_EMP_ID_PK
- JOB_HISTORY.REL_JOB_ID -> JOB_ID_PK
Now the query above with new schema and table names still returns no records although in our terms the detail record sets are different: EMPLOYEES has set (DEPT_ID_PK, JOB_ID_PK, EMP_EMP_ID_PK, EMP_EMP_ID_PK), while JOB_HISTORY has set (DEPT_ID_PK, JOB_ID_PK, JOB_ID_PK, EMP_EMP_ID_PK). The solution to this problem is of course that we need to group the detail records by the matching fields and add a count, as follows, using our copied schema HR_0:
SELECT r_owner,
r_constraint_name,
Count(*)
FROM con_cp
WHERE constraint_type = 'R'
AND table_name = 'EMPLOYEES'
AND owner = 'HR_0'
GROUP BY r_owner,
r_constraint_name
MINUS
SELECT r_owner,
r_constraint_name,
Count(*)
FROM con_cp
WHERE constraint_type = 'R'
AND table_name = 'JOB_HISTORY'
AND owner = 'HR_0'
GROUP BY r_owner,
r_constraint_name
This returns two records:
R_OWNER R_CONSTRAINT_NAME COUNT(*)
======= ================= ========
HR_0 EMP_EMP_ID_PK 2
HR_0 JOB_ID_PK 1
As for the first problem, this can be solved in two ways, either by repeating the NOT EXISTS clause with the two sections reversed, or by ensuring separately that the two record sets have the same numbers of records – if they don’t they can’t match, and if they do then the MINUS operator works. Obviously the first solution is going to double the work involved, while the second incurs a cost associated with the counting process but that’s offset by avoidance of the NOT EXISTS execution.
Matching Detail Sets with nested NOT EXISTS Operator
If we consider the MINUS query above before we added grouping, it seems likely that Oracle would evaluate the outer NOT EXISTS by obtaining both record sets, then applying the MINUS opersator, before checking that no records are returned. This would seem inefficient since the outer condition fails if any single record is in the first set but not in the second, so one would want to truncate processing on finding a first such record. This suggests an alternative that might be more effficient, that uses another NOT EXISTS nested within the outer one, which would apply to the following subquery:
SELECT 1
FROM con_cp c1
WHERE c1.constraint_type = 'R'
AND c1.table_name = 'OEHR_EMPLOYEES'
AND c1.owner = 'TWODAYPLUS_0'
AND NOT EXISTS (
SELECT 1
FROM con_cp c2
WHERE c2.constraint_type = 'R'
AND c2.table_name = 'OEHR_JOB_HISTORY'
AND c2.owner = 'TWODAYPLUS_0'
AND c2.r_owner = c1.r_owner
AND c2.r_constraint_name = c1.r_constraint_name
)
Here we have not included the grouping solution because it is complicated within this structure, but if the detail table were replaced by either a subquery factor or a temporary table where the grouping were already done, then (as we’ll see) this would work just by adding in an equality condition on the count fields. Again, if we know that the record counts are the same the reverse clause is unnecessary.
Pre-Matching Detail Sets by Aggregates
We noted above that the detail sets can only match if they have the same numbers of records, and that this could be used to avoid doing the set matching twice in opposite orders. We also noted that the work done in counting would be offset by the avoidance of expensive set matching for those pairs that don’t have matching counts. In fact, we can extend this idea to all possible aggregates on the detail record set matching fields, and this will likely result in fewer set matchings in the overall query execution. In our simple test problem we will add minimum and maximum aggregates on the r_constraint_name field, giving the following join conditions, prior to the set matching clause, and where tab represents a subquery factor that computes the aggregates:
FROM tab t1
JOIN tab t2
ON t2.n_det = t1.n_det
AND t2.min_det = t1.min_det
AND t2.max_det = t1.max_det
AND t2.row_id > t1.row_id
Subquery Factors and Temporary Tables
Owing to the importance of aggregation at table level, as explained in the last section above, all query variations considered will include a subquery factor, tab, that does this aggregation. However, we have also noted the need to group and count at the level of detail records, and as this grouped record set needs to be used twice, for each member of a potential matching master pair, it would also seem an obvious candidate for a subquery factor. When we try this though, we’ll see that the query structure now precludes the use of indexes within the detail matching subquery and so we’ll also implement a query that uses a temporary table where the grouping and counting is done in advance.
Query Variations
We will test five query variations, as shown below, where MI and NE denote, respectively, the MINUS and NOT EXISTS methods of detail set matching.
- INL_MI – Detail grouping directly
- SQF_NE – Detail grouping in subquery factor
- GTT_NE – Detail grouping in temporary table
- GTT_NE_X – As GRP_GTT_NE but table-level count aggregation only
- GTT_MI – As GRP_GTT_NE but with MINUS
************
INL_MI
************
WITH tab AS (
SELECT t.owner,
t.table_name,
t.ROWID row_id,
Count(c.ROWID) n_det,
Min (c.r_constraint_name) min_det,
Max (c.r_constraint_name) max_det
FROM tab_cp t
JOIN con_cp c
ON c.owner = t.owner
AND c.table_name = t.table_name
AND c.constraint_type = 'R'
GROUP BY
t.owner,
t.table_name,
t.ROWID
)
SELECT
t1.owner owner_1,
t1.table_name table_name_1,
t2.owner owner_2,
t2.table_name table_name_2,
t1.n_det n_det
FROM tab t1
JOIN tab t2
ON t2.n_det = t1.n_det
AND t2.min_det = t1.min_det
AND t2.max_det = t1.max_det
AND t2.row_id > t1.row_id
WHERE NOT EXISTS (
SELECT c2.r_owner,
c2.r_constraint_name,
Count(*)
FROM con_cp c2
WHERE c2.owner = t2.owner
AND c2.table_name = t2.table_name
AND c2.constraint_type = 'R'
GROUP BY c2.r_owner,
c2.r_constraint_name
MINUS
SELECT c1.r_owner,
c1.r_constraint_name,
Count(*)
FROM con_cp c1
WHERE c1.owner = t1.owner
AND c1.table_name = t1.table_name
AND c1.constraint_type = 'R'
GROUP BY c1.r_owner,
c1.r_constraint_name
)
ORDER BY t1.owner,
t1.table_name,
t2.owner,
t2.table_name
************
SQF_NE
************
WITH det AS (
SELECT owner,
table_name,
r_owner,
r_constraint_name,
Count(*) n_dup
FROM con_cp
WHERE constraint_type = 'R'
GROUP BY owner,
table_name,
r_owner,
r_constraint_name
), tab AS (
SELECT t.owner,
t.table_name,
t.ROWID row_id,
Sum (c.n_dup) n_det,
Min (c.r_constraint_name) min_det,
Max (c.r_constraint_name) max_det
FROM tab_cp t
JOIN det c
ON c.owner = t.owner
AND c.table_name = t.table_name
GROUP BY
t.owner,
t.table_name,
t.ROWID
)
SELECT
t1.owner owner_1,
t1.table_name table_name_1,
t2.owner owner_2,
t2.table_name table_name_2,
t1.n_det n_det
FROM tab t1
JOIN tab t2
ON t2.n_det = t1.n_det
AND t2.min_det = t1.min_det
AND t2.max_det = t1.max_det
AND t2.row_id > t1.row_id
WHERE NOT EXISTS (
SELECT 1
FROM det d1
WHERE d1.owner = t1.owner
AND d1.table_name = t1.table_name
AND (
NOT EXISTS (
SELECT 1
FROM det d2
WHERE d2.owner = t2.owner
AND d2.table_name = t2.table_name
AND d2.r_owner = d1.r_owner
AND d2.r_constraint_name = d1.r_constraint_name
AND d2.n_dup = d1.n_dup
)))
ORDER BY t1.owner,
t1.table_name,
t2.owner,
t2.table_name
************
GTT_NE
************
WITH tab AS (
SELECT t.owner,
t.table_name,
t.ROWID row_id,
Sum (c.n_con) n_det,
Min (c.r_constraint_name) min_det,
Max (c.r_constraint_name) max_det
FROM tab_cp t
JOIN grp_gtt c
ON c.owner = t.owner
AND c.table_name = t.table_name
GROUP BY
t.owner,
t.table_name,
t.ROWID
)
SELECT
t1.owner owner_1,
t1.table_name table_name_1,
t2.owner owner_2,
t2.table_name table_name_2,
t1.n_det n_det
FROM tab t1
JOIN tab t2
ON t2.n_det = t1.n_det
AND t2.min_det = t1.min_det
AND t2.max_det = t1.max_det
AND t2.row_id > t1.row_id
WHERE NOT EXISTS (
SELECT 1
FROM grp_gtt d1
WHERE d1.owner = t1.owner
AND d1.table_name = t1.table_name
AND (
NOT EXISTS (
SELECT 1
FROM grp_gtt d2
WHERE d2.owner = t2.owner
AND d2.table_name = t2.table_name
AND d2.r_owner = d1.r_owner
AND d2.r_constraint_name = d1.r_constraint_name
AND d2.n_con = d1.n_con
)))
ORDER BY t1.owner,
t1.table_name,
t2.owner,
t2.table_name
************
GTT_NE_X
************
WITH tab AS (
SELECT t.owner,
t.table_name,
t.ROWID row_id,
Sum (c.n_con) n_det
FROM tab_cp t
JOIN grp_gtt c
ON c.owner = t.owner
AND c.table_name = t.table_name
GROUP BY
t.owner,
t.table_name,
t.ROWID
)
SELECT
t1.owner owner_1,
t1.table_name table_name_1,
t2.owner owner_2,
t2.table_name table_name_2,
t1.n_det n_det
FROM tab t1
JOIN tab t2
ON t2.n_det = t1.n_det
AND t2.row_id > t1.row_id
WHERE NOT EXISTS (
SELECT 1
FROM grp_gtt d1
WHERE d1.owner = t1.owner
AND d1.table_name = t1.table_name
AND (
NOT EXISTS (
SELECT 1
FROM grp_gtt d2
WHERE d2.owner = t2.owner
AND d2.table_name = t2.table_name
AND d2.r_owner = d1.r_owner
AND d2.r_constraint_name = d1.r_constraint_name
AND d2.n_con = d1.n_con
)))
ORDER BY t1.owner,
t1.table_name,
t2.owner,
t2.table_name
************
GTT_MI
************
WITH tab AS (
SELECT t.owner,
t.table_name,
t.ROWID row_id,
Sum (c.n_con) n_det,
Min (c.r_constraint_name) min_det,
Max (c.r_constraint_name) max_det
FROM tab_cp t
JOIN grp_gtt c
ON c.owner = t.owner
AND c.table_name = t.table_name
GROUP BY
t.owner,
t.table_name,
t.ROWID
)
SELECT
t1.owner owner_1,
t1.table_name table_name_1,
t2.owner owner_2,
t2.table_name table_name_2,
t1.n_det n_det
FROM tab t1
JOIN tab t2
ON t2.n_det = t1.n_det
AND t2.min_det = t1.min_det
AND t2.max_det = t1.max_det
AND t2.row_id > t1.row_id
WHERE NOT EXISTS (
SELECT d2.r_owner,
d2.r_constraint_name,
d2.n_con
FROM grp_gtt d2
WHERE d2.owner = t2.owner
AND d2.table_name = t2.table_name
MINUS
SELECT d1.r_owner,
d1.r_constraint_name,
d1.n_con
FROM grp_gtt d1
WHERE d1.owner = t1.owner
AND d1.table_name = t1.table_name
)
ORDER BY t1.owner,
t1.table_name,
t2.owner,
t2.table_name
The query structure diagrams (QSDs) are in the embedded Excel file below:
Performance Analysis
We presented five query variations above, and in this section give the results of benchmarking these queries across a 1-dimensional data domain obtained by copying the system views 1, 2 and 4 times into my test tables described above. The problem sizes are as follows:
Record Counts
Timings and Statistics
Click on the query name in the file below to jump to the execution plan for the largest data point.
Comparison
The timings above are only for the main queries, so we need also to consider the time to populate and delete the temporary table, for the three GTT queries. This is performed as part of the data point setup, and the framework prints out timings for this part separately. For the last data point, the output was:
5144 records inserted in grp_gtt
8956 tables, 44780 constraints, 5 c/t
Timer Set: Setup, Constructed at 09 Oct 2012 22:28:49, written at 22:29:04
==========================================================================
[Timer timed: Elapsed (per call): 0.05 (0.000047), CPU (per call): 0.05 (0.000050), calls: 1000, '***' denotes corrected line below]
Timer Elapsed CPU Calls Ela/Call CPU/Call
----------------- ---------- ---------- ------------ ------------- -------------
Delete test data 3.33 2.78 1 3.33200 2.78000
Delete GTT 0.18 0.17 1 0.18000 0.17000
Insert tab 0.55 0.44 1 0.54500 0.44000
Insert con 7.89 5.94 1 7.89000 5.94000
Insert grp_gtt 0.14 0.14 1 0.14000 0.14000
Count records 0.02 0.01 1 0.01600 0.01000
Gather statistics 2.59 2.06 1 2.58900 2.06000
(Other) 0.00 0.00 1 0.00000 0.00000
----------------- ---------- ---------- ------------ ------------- -------------
Total 14.69 11.54 8 1.83650 1.44250
----------------- ---------- ---------- ------------ ------------- -------------
The elapsed times for deleting from, then inserting into the temporary table are given by the ‘Delete GTT’ and ‘Insert grp_gtt’ timers and add up to 0.32s, so do not make much difference (about 5% on the best and less on the others). The following points can be made:
- Doing the detail grouping and counting directly gives the worst performance
- Moving the detail grouping and counting into a subquery factor improves performance by a factor of about 4
- Moving the detail grouping into a temporary table improves performance the most
- Using NOT EXISTS instead of MINUS for detail matching improves performance, as expected, by a factor of about 2
- Using the minimum and maximum aggregates for pre-filtering, in addition to the counts, improves performance by a factor of about 20
Subquery Factors and Temporary Tables
If you look at the execution plan for INL_MI, most of the work is done in the HASH GROUP BY steps, 16 and 20, on totals of 127K records each. Moving this grouping into a subquery factor in SQF_NE means that the operation is done only once rather than many times (110K), and the execution plan for SUBQ_NE shows that it takes very little time (line 3).
However, the execution plan for SUBQ_NE shows (lines 14-22) that the factors are read using full scans, because indexes are not possible. This observation led to the improvement of moving the grouping out of the query altogether and into a separate stage that populates a temporary table, on which indexes can be defined. Lines 15-18 in the plan for GTT_NE show the access is now by index on the detail records.
Memory Usage in INL_MI Query with Grouping
Originally, I tried to have a larger range of data points, but doubling the size again always resulted in an Oracle error on INL_MI, ORA-04030: out of process memory when trying to allocate 123404 bytes (QERGH hash-agg,kllcqas:kllsltba). This is surprising because the execution plan statistics include memory statistics that appear to indicate that all queries use the same maximum amount of memory, which is just over 3MB, incurred in the SORT ORDER BY step (e.g. line 7 below).
My framework also collects statistics from the system view v$mystat, and prints out those showing large variations in ‘after minus before’ differences across the queries. The framework printed the statistic ‘session pga memory’ and this tells a different story (the values are in the embedded Excel files under Statistics above). The INL_MI query shows increases of 14MB, then 170MB, then 768MB approx. while the other queries all show no increases. It’s hard to understand what’s going on here, but one guess is that the query is revealing an Oracle bug that causes memory not to be released after use and then re-used, but for new executions of the relevant operation to request new memory, and that the execution plans are not reporting this. However, as discussed later, the variation in execution time with problem size is also difficult to understand and suggests that the HASH GROUP BY operations are really being performed on the entire record sets, which would also greatly increase the memory usage. The version, running under Windows 7 is: Oracle Database 11g Express Edition Release 11.2.0.2.0 – Beta
Execution Plan Hash Values
In my last article, I was able to easily identify the distinct plans by looking at the matrix of plan hash values, with values the same indicating the same plan. This time though, that doesn’t work: all hash values are different, but in fact, inspection of the plans shows that for each query there was essentially only one plan. I believe this may be due to the subquery factors, which result in a system-generated view name, which differs each time. For example, here are the last two plans for the INL_MI, where the only difference appears to be in the view names (SYS_TEMP_0FD9D6681_1B0CFB4 for W2 and SYS_TEMP_0FD9D6687_1B0CFB4 for W4) (note that different statistics don’t make the plans different):
Point W2:
Plan hash value: 89269728
-----------------------------------------------------------------------------------------------------------------------------------------------------------------------
| Id | Operation | Name | Starts | E-Rows | A-Rows | A-Time | Buffers | Reads | Writes | OMem | 1Mem | Used-Mem |
-----------------------------------------------------------------------------------------------------------------------------------------------------------------------
| 0 | SELECT STATEMENT | | 1 | | 8054 |00:01:40.96 | 191K| 21 | 21 | | | |
| 1 | TEMP TABLE TRANSFORMATION | | 1 | | 8054 |00:01:40.96 | 191K| 21 | 21 | | | |
| 2 | LOAD AS SELECT | | 1 | | 0 |00:00:00.05 | 3182 | 0 | 21 | 264K| 264K| 264K (0)|
| 3 | HASH GROUP BY | | 1 | 2606 | 1628 |00:00:00.05 | 3158 | 0 | 0 | 766K| 766K| 1273K (0)|
| 4 | NESTED LOOPS | | 1 | 2606 | 2606 |00:00:00.05 | 3158 | 0 | 0 | | | |
|* 5 | TABLE ACCESS FULL | CON_CP | 1 | 2606 | 2606 |00:00:00.01 | 625 | 0 | 0 | | | |
|* 6 | INDEX UNIQUE SCAN | TCP_PK | 2606 | 1 | 2606 |00:00:00.02 | 2533 | 0 | 0 | | | |
| 7 | SORT ORDER BY | | 1 | 1 | 8054 |00:01:40.89 | 188K| 21 | 0 | 1824K| 650K| 1621K (0)|
|* 8 | FILTER | | 1 | | 8054 |00:01:24.17 | 188K| 21 | 0 | | | |
|* 9 | HASH JOIN | | 1 | 1 | 27242 |00:00:00.15 | 47 | 21 | 0 | 720K| 720K| 1282K (0)|
| 10 | VIEW | | 1 | 2606 | 1628 |00:00:00.01 | 25 | 21 | 0 | | | |
| 11 | TABLE ACCESS FULL | SYS_TEMP_0FD9D6681_1B0CFB4 | 1 | 2606 | 1628 |00:00:00.01 | 25 | 21 | 0 | | | |
| 12 | VIEW | | 1 | 2606 | 1628 |00:00:00.01 | 22 | 0 | 0 | | | |
| 13 | TABLE ACCESS FULL | SYS_TEMP_0FD9D6681_1B0CFB4 | 1 | 2606 | 1628 |00:00:00.01 | 22 | 0 | 0 | | | |
| 14 | MINUS | | 27242 | | 19188 |00:01:40.05 | 188K| 0 | 0 | | | |
| 15 | SORT UNIQUE | | 27242 | 1 | 28722 |00:00:53.68 | 73872 | 0 | 0 | 2048 | 2048 | 2048 (0)|
| 16 | HASH GROUP BY | | 27242 | 1 | 31314 |00:00:45.36 | 73872 | 0 | 0 | 750K| 750K| 610K (0)|
|* 17 | TABLE ACCESS BY INDEX ROWID| CON_CP | 27242 | 1 | 31335 |00:00:01.57 | 73872 | 0 | 0 | | | |
|* 18 | INDEX RANGE SCAN | CON_TAB_FK_N1 | 27242 | 1 | 175K|00:00:01.26 | 42504 | 0 | 0 | | | |
| 19 | SORT UNIQUE | | 27242 | 1 | 30502 |00:00:45.94 | 114K| 0 | 0 | 2048 | 2048 | 2048 (0)|
| 20 | HASH GROUP BY | | 27242 | 1 | 31314 |00:00:37.86 | 114K| 0 | 0 | 750K| 750K| 910K (0)|
|* 21 | TABLE ACCESS BY INDEX ROWID| CON_CP | 27242 | 1 | 31335 |00:00:01.64 | 114K| 0 | 0 | | | |
|* 22 | INDEX RANGE SCAN | CON_TAB_FK_N1 | 27242 | 1 | 183K|00:00:01.29 | 83068 | 0 | 0 | | | |
-----------------------------------------------------------------------------------------------------------------------------------------------------------------------
Predicate Information (identified by operation id):
---------------------------------------------------
5 - filter("C"."CONSTRAINT_TYPE"='R')
6 - access("C"."OWNER"="T"."OWNER" AND "C"."TABLE_NAME"="T"."TABLE_NAME")
8 - filter( IS NULL)
9 - access("T2"."N_DET"="T1"."N_DET" AND "T2"."MIN_DET"="T1"."MIN_DET" AND "T2"."MAX_DET"="T1"."MAX_DET")
filter("T2"."ROW_ID">"T1"."ROW_ID")
17 - filter("C2"."CONSTRAINT_TYPE"='R')
18 - access("C2"."OWNER"=:B1 AND "C2"."TABLE_NAME"=:B2)
21 - filter("C1"."CONSTRAINT_TYPE"='R')
22 - access("C1"."OWNER"=:B1 AND "C1"."TABLE_NAME"=:B2)
Point W4:
Plan hash value: 892071883
-----------------------------------------------------------------------------------------------------------------------------------------------------------------------
| Id | Operation | Name | Starts | E-Rows | A-Rows | A-Time | Buffers | Reads | Writes | OMem | 1Mem | Used-Mem |
-----------------------------------------------------------------------------------------------------------------------------------------------------------------------
| 0 | SELECT STATEMENT | | 1 | | 16108 |00:25:33.98 | 788K| 42 | 42 | | | |
| 1 | TEMP TABLE TRANSFORMATION | | 1 | | 16108 |00:25:33.98 | 788K| 42 | 42 | | | |
| 2 | LOAD AS SELECT | | 1 | | 0 |00:00:00.10 | 5802 | 0 | 42 | 521K| 521K| 521K (0)|
| 3 | HASH GROUP BY | | 1 | 5007 | 3256 |00:00:00.09 | 5757 | 0 | 0 | 1001K| 943K| 1273K (0)|
| 4 | NESTED LOOPS | | 1 | 5007 | 5212 |00:00:00.09 | 5757 | 0 | 0 | | | |
|* 5 | TABLE ACCESS FULL | CON_CP | 1 | 4980 | 5212 |00:00:00.01 | 625 | 0 | 0 | | | |
|* 6 | INDEX UNIQUE SCAN | TCP_PK | 5212 | 1 | 5212 |00:00:00.04 | 5132 | 0 | 0 | | | |
| 7 | SORT ORDER BY | | 1 | 1 | 16108 |00:25:33.84 | 782K| 42 | 0 | 3596K| 822K| 3196K (0)|
|* 8 | FILTER | | 1 | | 16108 |00:22:30.61 | 782K| 42 | 0 | | | |
|* 9 | HASH JOIN | | 1 | 1 | 110K|00:00:00.62 | 89 | 42 | 0 | 900K| 900K| 1328K (0)|
| 10 | VIEW | | 1 | 5007 | 3256 |00:00:00.02 | 46 | 42 | 0 | | | |
| 11 | TABLE ACCESS FULL | SYS_TEMP_0FD9D6687_1B0CFB4 | 1 | 5007 | 3256 |00:00:00.01 | 46 | 42 | 0 | | | |
| 12 | VIEW | | 1 | 5007 | 3256 |00:00:00.03 | 43 | 0 | 0 | | | |
| 13 | TABLE ACCESS FULL | SYS_TEMP_0FD9D6687_1B0CFB4 | 1 | 5007 | 3256 |00:00:00.02 | 43 | 0 | 0 | | | |
| 14 | MINUS | | 110K| | 94488 |00:25:29.91 | 782K| 0 | 0 | | | |
| 15 | SORT UNIQUE | | 110K| 1 | 113K|00:14:20.41 | 300K| 0 | 0 | 2048 | 2048 | 2048 (0)|
| 16 | HASH GROUP BY | | 110K| 1 | 127K|00:11:47.70 | 300K| 0 | 0 | 789K| 789K| 527K (0)|
|* 17 | TABLE ACCESS BY INDEX ROWID| CON_CP | 110K| 1 | 127K|00:00:08.15 | 300K| 0 | 0 | | | |
|* 18 | INDEX RANGE SCAN | CON_TAB_FK_N1 | 110K| 1 | 722K|00:00:06.55 | 156K| 0 | 0 | | | |
| 19 | SORT UNIQUE | | 110K| 1 | 123K|00:11:07.57 | 481K| 0 | 0 | 2048 | 2048 | 2048 (0)|
| 20 | HASH GROUP BY | | 110K| 1 | 127K|00:09:52.37 | 481K| 0 | 0 | 789K| 789K| 907K (0)|
|* 21 | TABLE ACCESS BY INDEX ROWID| CON_CP | 110K| 1 | 127K|00:00:08.37 | 481K| 0 | 0 | | | |
|* 22 | INDEX RANGE SCAN | CON_TAB_FK_N1 | 110K| 1 | 735K|00:00:06.31 | 337K| 0 | 0 | | | |
-----------------------------------------------------------------------------------------------------------------------------------------------------------------------
Predicate Information (identified by operation id):
---------------------------------------------------
5 - filter("C"."CONSTRAINT_TYPE"='R')
6 - access("C"."OWNER"="T"."OWNER" AND "C"."TABLE_NAME"="T"."TABLE_NAME")
8 - filter( IS NULL)
9 - access("T2"."N_DET"="T1"."N_DET" AND "T2"."MIN_DET"="T1"."MIN_DET" AND "T2"."MAX_DET"="T1"."MAX_DET")
filter("T2"."ROW_ID">"T1"."ROW_ID")
17 - filter("C2"."CONSTRAINT_TYPE"='R')
18 - access("C2"."OWNER"=:B1 AND "C2"."TABLE_NAME"=:B2)
21 - filter("C1"."CONSTRAINT_TYPE"='R')
22 - access("C1"."OWNER"=:B1 AND "C1"."TABLE_NAME"=:B2)
Performance Variation Polynomials
The timings above show that CPU and elapsed times increased by different powers of the problem size increases, according to query.
The inline grouping query INL_MI shows a variation close to the fourth power, which like its memory usage, is very hard to understand. Most of the time is used in the HASH GROUP BY operations at lines 16 and 20, and it rises about 16 times betwen W2 and W4. The numbers of starts rise by 4 times, as expected, but the number of rows per start remains constant at about 1.15, so the work done should rise by about 4 times. It’s almost as though the SQL engine is really processing the entire record set in the HASH GROUP BY, rather than just the subset for the correlated tables, contrary to what the plan says. Again, this looks buggy.
The double subquery factor query SUBQ_NE has about a cubic variation, which is plausible because the table pairing introduces a quadratic term, with the third power coming from the full scans of the detail subquery factor.
All three of the temporary table queries show quadratic variation, which is likely the best obtainable while matching sets directly (but see my next article Holographic Set Matching in SQL for linear solutions bypassing set matching), and arises from the table pairing, but with the details for each pair being constant in size and accessed via indexes. It’s worth noting that the query GTT_NE_X is actually slower than INL_MI and SUB_NE on the smallest data point, but much quicker on the largest, showing the importance of polynomial order for scalability.
Conclusions
- We have shown how to solve master-detail transaction matching problems efficiently, using an example problem, but emphasising the generality of the techniques
- Appropriate use of subquery factors and temporary tables have been demonstrated, with performance analysis
- It’s worth highlighting the technique of pre-filtering on aggregates before comparing sets in detail
- The importance for scalability of performance variation powers has been illustrated, being revealed by dimensional benchmarking
- On finishing this article it occurred to me to wonder whether it might not be possible to use aggregate matching to replace detail set matching altogether, and at least in some cases it is, with linear performance resulting, described in my next article, Holographic Set Matching in SQL (MDTM2)