[This article was migrated to the author’s GitHub Pages site here in July 2025]
In a recent article, A Design Pattern for Oracle eBusiness Audit Trail Reports with XML Publisher, I presented a report that I developed within Oracle eBusiness 12.1, using Oracle XML Publisher. The report was for displaying audit trail data for a particular table, and I proposed that it could be used as a design pattern for audit trail reporting on any eBusiness table. The article focussed on the rather complex SQL, with associated layout structures, needed to render the audit data into a readable format.
In this article, I present a pair of XML Publisher reports intended to serve as design patterns for more general reporting. The reports were again developed within the framework of Oracle’s eBusiness embedded version of XML Publisher, of which there is also a stand-alone version,
Oracle Business Intelligence Publisher, which describes the product (rather ungrammatically) thus:
Oracle BI Publisher is the reporting solution to author, manage, and deliver all your reports and documents easier and faster than traditional reporting tools.
Reports Overview
The reports were developed specifically to serve as models for other reports, from which program constructs could be copied and pasted. For this reason I considered taking for the data sources universally available Oracle metadata such as all_tables or all_objects etc., but found problems with that idea, including:
- They are not generally ordinary tables, and tend to produce very complex execution plans
- The possible group structures I found were not quite general enough for my purposes
On the other hand, within Oracle eBusiness I had a number of queries available against the (FND application) metadata tables for concurrent programs that seemed to fit the purpose pretty well, and so decided to use these. As a compromise I created views on the tables with generic column names, so that the reports could be ported to other data sources relatively easily.
Concurrent Programs Data Model
In Oracle eBusiness applications concurrent (i.e. batch) programs have a logical metadata record for the program itself, and (potentially) a set of records for each of the following associated entities:
- Parameter
- Request group
- XML layout template
All of these can have zero records, and for the third entity, only programs of specific type can have any records defined, a structure providing a reasonable degree of generality.
Email Bursting
Business application reports are often used to generate documents for sending to customers, suppliers etc., and increasingly companies prefer to email these out to save costs compared with mailing printed documents. In the past report developers had to code the emailing functionality themselves, usually by means of a co-ordinating program that would loop over the master records and call the reporting tool individually for each one, creating an attachment file that would then be emailed, perhaps by the Unix mailx program. As well as the development effort involved, this approach had the drawback that it scales badly as the number of emails rises owing to the individual calls to the reporting tool (such as Oracle Reports). A printed report will frequently create 10,000 records in little more time than for 1,000 records, whereas for the hand-coded emailing process it would likely take 10 times longer.
The bursting functionality in Oracle XML Publisher solves these problems by allowing the emailing processing to be specified by an XML configuration file, and by creating the files to be emailed in batch just as with printed reports. The data files are created initially in XML format from the data model, and are then merged with layout templates that are emailed by a second program.
The design pattern reports will consist of an email bursting version with a printed version, which would generally be required as a fallback for records with missing or invalid email addresses. We’ll address the obvious security issue with automated emailing programs as part of our design pattern below.
Report Outputs
Examples of complete report outputs for the printed report in .pdf format are included in the attached zip file. Here three pages are given, two showing the listing for the example report programs themselves, and a third showing a non-XML program.
Example Report – XX Example XML CP
This is page 8 of the printed report run with the only the first parameter set, the application.
- Only the parameters that were actually set are listed after the title
- The templates region appears because it is an XML report
- There is only one template for this printed report, with XSL conditionality to include or exclude regions or columns

Example Report – XX Example XML CP (Email)
This is page 9 of the printed report run with the only the first parameter set, the application.
- Notice that the bursting file column appears because this report has the file attached, using XSL conditionality
- This email version has two layout templates that are used conditionally for each record depending on whether it’s of XML type or not
- This record-level choice of template is implemented in the bursting XML file, and is not available in this way for the printed version

Advanced Pricing Report – QP: Java Pricing Engine Warm Up
This is page 44 of the printed report run for the Advanced Pricing application.
- It shows a non-XML program, and the templates region consequently does not appear
- Notice that only the summary line appears for the parameters as there are no parameters defined for the program.

XML Data Templates and XML Generators
XML Publisher reports require at least one layout template in one of several formats, and also require an executable program to generate the XML data file to merge with the template(s). Oracle supplies a Java executable to generate the data file from an XML data template containing the SQL queries, group structure etc. that the programmer attaches to the concurrent program. This is usually the best approach since it mimimizes the amount of programming required.
It is also possible to use Oracle Reports to generate XML. This can be a reasonable approach for converting legacy reports to XML Publisher to avail of some of the additional features, such as Excel output and email bursting. However, if the data model needs changing it is probably best to extract the SQL and create an XML data template from it.
It’s a really bad idea to write a PL/SQL program to generate the XML data file, being a serious case of ‘reinventing the wheel’ – use Oracle’s Java executable with XML data template instead!
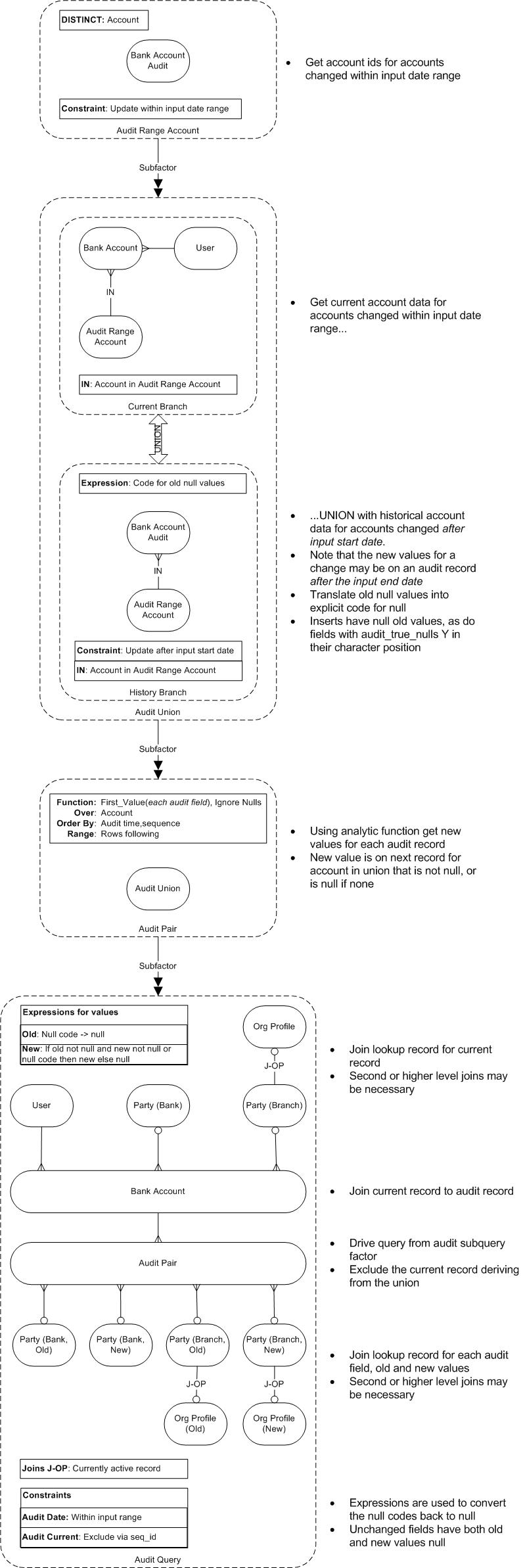
Data Model: Groups, Queries, Parameters, Summaries
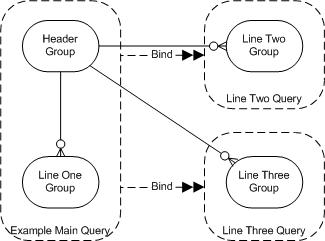
As described above, the example report has one master data group and three detail groups. As discussed in my last article Query Query Query, the minimum number of queries required for a group structure hierarchy is the number of groups minus the number of parent groups, which equals three here. The group structure with detail queries linked by bind variables could be depicted as below.
Group Structure Diagram
A possible query structure for the three queries might then look like the following, where I have included summaries for two of the detail groups, and allowed for report constraints via lexical parameters, to be discussed later.
Query Structure Diagram

Query Links and Bind Variables
It is possible to link detail queries to their master by XML query links, but according to the manual Oracle® XML Publisher Administration and Developer’s Guide, Release 12:
XML Publisher tests have shown that using bind variables is more efficient than using the link tag.
Linking a detail query to its master by bind variables involves simply referencing the master variable link columns within the detail query preceded by a colon.
Constraints and Parameters
Reports often have constraints depending on input parameters, which may be mandatory or optional. Input parameters are defined in a parameters section within the data template.
Mandatory parameters can be referenced directly as bind variables within the queries (i.e. by preceding the parameter name with a colon).
Optional parameters should normally be referenced indirectly using additional lexical parameters. This allows the exact query required to be executed rather than a composite query with Nvls to represent all possible query combinations. The latter all-purpose queries tend to be more complex and to perform poorly. Lexical parameters are declared and processed in the associated database package, and referenced by preceding them with an ampersand (&).
Note that, confusingly, these lexical parameters are not the same as the lexical tags applicable only within eBusiness that refer to eBusiness flexfields. Like the corresponding user-exits in eBusiness Oracle Reports the lexical tags allow flexfields to be included without their structure being known to the report developer. This is necessary for the standard eBusiness reports but developers of custom reports normally know the structures, and so can avoid these tags altogether (at least for new reports).
Summaries
There are various ways of computing summaries in XML Publisher reports:
- Within the SQL
- within the XML group elements
- within the layout template
SQL Summaries
Often the best way to do the summaries is in the SQL itself. This makes testing simpler because the queries can be run and debugged in SQL Developer or Toad, and also facilitates production support where developers can often run queries in a read-only schema, but can’t change the production code.
In the simple case of summarising detail groups that are defined against a main query, the summaries can be done using analytic functions partitioning by the master key for first level details, and as desired for any subsequent levels. In my example reports, Example Line One is summarised in this way; a subquery factor was used but this is optional here.
Groups defined against additional queries cannot be summarised quite so easily in the SQL. I have summarised the Example Line Two group by adding a subquery factor in the main query purely to do the summaries: Because the line detail is not present in the query we can’t do this by analytic functions, so a grouping summary in a separate subquery is necessary.
XML Group Summaries
Where possible SQL summaries via analytic functions appears best, but in other cases we may wish to consider the non-SQL alternatives. One of these is to define the summaries within the appropriate group as elements in the XML template setting the value attribute to the element in the lower level group to be summarised, and setting the function attribute as desired within a limited set of functions. I have not implemented this method in my examples.
XSL Layout Summaries
A further non-SQL alternative for summaries is to define them within the layout template using the XSL language, and I have implemented the summaries of Example Line Three using this method.
Database Package and Report Triggers
Each XML Publisher has a default package specified in the XML template, that handles parameter processing and implements any triggers required.
Package Spec
The spec declares both input parameters and lexical parameters, as well as the procedures that implement the report triggers (usually three).
Triggers
Before Report
- This trigger is used to process the lexical parameters, constructing the appropriate where condition depending on which optional parameters have values
- The example packages show how ranges of character, date and number are processed. I have found it more convenient to pass dates as string parameters.
After Report
- This trigger can be used to write column headings to the log file for fields that are logged in the group filter
Group Filter
- This trigger can be used to filter out records depending on some condition, by returning FALSE.
- I use it in the examples to log selected fields for each record returned.
- This logging is particularly important for email bursting reports as it enables checking that emails to be sent externally are appropriate before sending in a second step.
Printed Example Report Details
Report Parameters
The report parameters were designed to illustrate the implementation of character, date and number ranges, with an equality join parameter that fits well with the report content, all optional:
- Application – the eBusiness application id
- Program name From and To parameters – character range
- Creation date From and To parameters – date range
- Number of parameters From and To parameters – number range
Where there is an associated email version it may be worth having an additional Yes/No parameter determining whether to include records that have an email address defined.
Layout Template
There is a single layout template, of .rtf format.
Layout Template Structure

Layout Template File
Loading...
Notes on Layout
- Body and Margins
- The page numbers are in the bottom margin (or footer)
- The title, parameters and header fields are above the body tag, and repeat on each page of a given header record
- Conditional Blocks and Columns
- XSL if-blocks are used to conditionally print blocks such as input parameters, or detail tables depending on data values
- XSL if-blocks with column qualifiers are used to conditionally print table columns: If there is no bursting file, the entire bursting file column will not appear
- Sections and Page Breaks
- The XSL for-each field for the header group uses the section qualifier, which, in conjunction with the page break field, specifies a new page after each header record except the last
- By default, the above section qualifier would specify that page numbers reset with each header record, but this is overriden here by the initial-page-number field in the footer
- XSL Summary
- As discussed in the data model section, the line three summary is implemented in XSL – by the XSL count field
Email Bursting Example Report
Email Address Parameters
In addition to the printed report constraint parameters, three email address parameters have been added.
- Override email address – setting a value here overrides the record level email address and is useful for testing
- From and CC email addresses are parameters, which can be defaulted, for flexibility
- The email address data source is hard-coded in this demo report: normally it would be something like a supplier email address at master record level
Two Step Bursting Process
The first step is to run the concurrent program for the report, which results in an XML file containing the report data to be created on the server. In the second step, a standard concurrent program ‘XML Publisher Report Bursting Program’ is run, passing the request id of the earlier custom report, in order to merge the XML data file with the layout template(s) and send the individual reports by email.
It’s sometimes recommended to trigger the running of the second program within the custom report itself, but it’s probably better not to do this, in order to allow validation of the reports and email addresses before sending them out.
Email Report Logging
The example report logs the email address and other fields in the concurrent program log file, including whether an override email address was specified, where the user can check them before executing the second step that sends out the emails.
Layout Template
There are two layout templates, of .rtf format, which are used conditionally depending on the type of record. The structure of the one used for XML type programs (shown below) has conditional header fields and the third lines block that are absent from the other (not shown).
Layout Template Structure

Layout Template File
Loading...
Notes on Layout
- The master group is excluded from the template, although its fields are present in the header. The XML Publisher bursting program performs the looping over this group
Email Bursting XML File
<xapi:requestset xmlns:xapi="http://xmlns.oracle.com/oxp/xapi" type="bursting">
<xapi:request select="/XX_ERPXMLCP_EM/LIST_G_HDR/G_HDR">
<xapi:delivery>
<xapi:email server="127.0.0.1" port="25" from="${FROM_EMAIL}" reply-to ="">
<xapi:message id="123" to="${EMAIL_ADDRESS}" cc="${CC_EMAIL}"
attachment="true" subject="${SUB}">Dear Sir/Madam
Pleae find attached your concurrent program details.
[Alternatively, leave blank and use output_type=html in document to have attachment go to body instead]</xapi:message>
</xapi:email>
</xapi:delivery>
<xapi:document output="CP_${PROG_NAME}.pdf" output-type="pdf" delivery="123">
<xapi:template type="rtf" location="XDO://CUSTOM.XX_ERPXMLCP_EM.en.US/?getSource=true" filter="//G_HDR[OUTPUT_TYPE!='XML']"></xapi:template>
<xapi:template type="rtf" location="XDO://CUSTOM.XX_ERPXMLCP_EM_XML.en.US/?getSource=true" filter="//G_HDR[OUTPUT_TYPE='XML']"></xapi:template>
</xapi:document>
</xapi:request>
</xapi:requestset>
Notes on Bursting File
- The email server is specified in the bursting XML configuration file, along with the email addresses to be used, which can be variables from the selected records or hard-coded
- The layout template is specified, and more than one can be included, as here, with filter conditions depending on selected data fields
- Here the output is specified to be sent as a .pdf attachment; changing to output type html results in the the output appearing as body text
- It can be useful to store some or all of the subject (or body) text on the database; the table fnd_messages is used to store the subject here, as records from the fnd tables can be installed automatically via fndload
Code to Download
The zip file Brendan_Model_XML_Reports contains a root folder and three subfolders, as follows:
- Root – MD120 installation document for the email version. It references a generic Unix script that installs all objects, see A Generic Unix Script for Uploading Oracle eBusiness Concurrent Programs
- Output – examples of log files for both printed and email versions and pdf outputs for printed version
- XX_ERPXMLCP – complete code and metadata for the printed version
- XX_ERPXMLCP_EM – complete code and metadata for the email version (except requires some printed version objects to be installed first)