
[This article was migrated to the author’s GitHub Pages site here in August 2025]
I saw a link a week ago or so on my Twitter feed to an article published by one Lance Gutteridge on 1 June 2018: What I’m Telling Business People About Why Relational Databases Are So Bad. The article is written in a inflammatory style, here’s a sample quote:
Relational databases have been the worst technology to ever poison a field of endeavor
He classifies the ‘badness’ in three main categories:
- SQL Injection
- SQL “is a total violation of the DRY principle”
- Object-Relational Impedance Mismatch
In this article I want to briefly discuss his criticisms under each of these categories, and then move on to discuss some interesting features of SQL queries and joins arising from the fact that SQL plainly does NOT violate the DRY principle. I’ll also discuss how the concept of the network, initially applied to table relationships, can be a very useful design concept in both data modelling and query design.
Part I: Comments on the Lance Gutteridge article
SQL Injection
From Wikipedia, SQL injection:
SQL injection is a code injection technique, used to attack data-driven applications, in which nefarious SQL statements are inserted into an entry field for execution (e.g. to dump the database contents to the attacker).
SQL injection has indeed been a real vulnerability for database systems in the past, but it is an avoidable problem today. As the Wikipedia article puts it:
An SQL injection is a well known attack and easily prevented by simple measures.
SQL “is a total violation of the DRY principle”
Dr. Gutteridge notes that relationships are defined in an RDBMS by foreign keys and primary keys on the tables, and that having to make join relations explicitly in SQL is a repetition of information already known, and hence violates the “Don’t Repeat Yourself” principle.
This criticism is easily dealt with: In general the table relationships do not in fact fully determine the joins in a query. A simple, and very common, example arises in order entry systems. Consider the following simplified 3-table data model:

Here we have an order entity with a foreign key link to a customer, and two foreign key links to the address entity. A customer may have multiple addresses that can serve as shipping or billing addresses on any given order. A particular query may require one or other, or both, or neither of the addresses for the order. The primary key/foreign key relationships cannot determine which tables and links to include without the query specifying them.
The usual way to specify this information in ANSI-standard SQL is to use JOIN/ON-clauses like this:
JOIN addresses add_b ON add_b.address_id = ord.billing_address_id
There are also situations in which joins can be expressed more concisely, and we’ll look at some of them in part II, but it’s clear that these clauses do not in any meaningful way violate the DRY principle.
Object-Relational Impedance Mismatch
In one of the few views on which I am inclined to agree with Dr. Gutteridge, he regards the term as “technobabble”, but it does describe a real phenomenon. Dr. Gutteridge expresses it thus:
…the data in a relational database is stored in ways more in keeping with a 1980s programming language than with a modern, object-oriented language
Though this mismatch does exist, it’s unlikely that dropping the relational model is the answer, because it solves a more fundamental problem. An article from 29 November 2017, Important Papers: Codd and the Relational Model, includes the following:
…Codd motivates the search for a better model by arguing that we need “data independence,” which he defines as “the independence of application programs and terminal activities from growth in data types and changes in data representation.” The relational model, he argues, “appears to be superior in several respects to the graph or network model presently in vogue,” partly because, among other benefits, the relational model “provides a means of describing data with its natural structure only.” By this he meant that programs could safely ignore any artificial structures (like trees) imposed upon the data for storage and retrieval purposes only.
I remember when I started my programming career in 1984 most of the work on any application was spent in writing code simply to store and retrieve data in application-specific formats. Within a few years that effort became largely unnecessary with the introduction of the Oracle RDBMS and SQL. Although modern big data requirements mean other approaches to data storage are also needed, the relational model isn’t going away.
In one of the unwitting ironies in Dr. Gutteridge’s article, he states towards the end that:
there are programmers who have never really seen any other kind of database and believe that all databases are relational
while apparently believing that all modern programming language are object-oriented. They aren’t, and while OOP isn’t going away, it has real deficiencies in modelling the real world that have led to growing interest in other paradigms such as functional programming, as well as old fashioned imperative programming. Here’s an interesting review of some of those deficiencies from 23 July 2016:
Goodbye, Object Oriented Programming
Part II: On SQL and DRY – Joins via NATURAL/USING/ON
In this second part we’ll use two subsets of Oracle’s HR demo schema as examples, and we’ll ignore any links in the tables to tables other than those depicted in the ERDs. Let’s see how, in some cases, we can use ANSI join syntax to avoid explicitly listing all the join column names, but that there are drawbacks to doing so.
Tree Data Model – Department 110, Location, Country, Region – NATURAL JOIN
The ERD below shows a simple linear tree structure.

Let’s start by considering a situation where we don’t need to specify the full join clause with fields on both sides.
DEPARTMENT_NAME STREET_ADDRESS CITY COUNTRY_NAME REGION_NAME ------------------------------ ---------------------------------------- ------------------------------ ---------------------------------------- ------------------------- Accounting 2004 Charade Rd Seattle United States of America Americas 1 SELECT department_name, street_address, city, country_name, region_name 2 FROM departments 3 NATURAL JOIN locations 4 NATURAL JOIN countries 5 NATURAL JOIN regions 6* WHERE department_id = 110
Here in this simple (linear) tree-structured data model we were able to join the three subsequent tables to the driving table, departments, simply by adding the table names after NATURAL JOIN.
So is this a case of the SQL engine reading the data model and constructing the joins without the need for repetition? No, it isn’t. As the documentation tells you, NATURAL JOIN joins by matching fields with the same names on either side. This can be dangerous as the next example shows.
The second example has only two tables, but there is a loop in the structure.
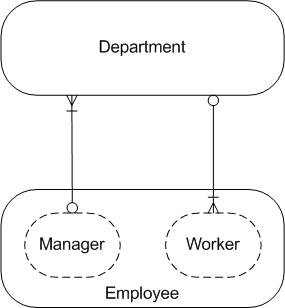
[In the underlying HR schema from which this is extracted there is also a self-join on employees, which we are excluding]
Department 110 employees: NATURAL JOIN gives wrong answer
There are two employees in department 110:
COUNT(*)
----------
2
1 SELECT COUNT(*)
2 FROM employees
3* WHERE department_id = 110
Let’s try to get the employees using NATURAL JOIN, like this:
DEPARTMENT_NAME LAST_NAME FIRST_NAME MANAGER_ID ------------------------------ ------------------------- -------------------- ---------- Accounting Gietz William 205 1 SELECT department_name, last_name, first_name, manager_id 2 FROM departments 3 NATURAL JOIN employees 4* WHERE department_id = 110
This returns only one of the two employees because NATURAL JOIN is matching on both department_id and manager_id as they appear in both tables.
Department 110 employees: USING department_id gives right answer
We can get the right answer by joining with the USING keyword, which assumes the column name to join on is the same on both tables, and mentions it explicitly.
DEPARTMENT_NAME LAST_NAME FIRST_NAME ------------------------------ ------------------------- -------------------- Accounting Higgins Shelley Accounting Gietz William 1 SELECT department_name, last_name, first_name 2 FROM departments 3 JOIN employees USING (department_id) 4* WHERE department_id = 110
This example shows how USING resolves the earlier NATURAL JOIN error by specifying the field names in common to be used. The next example shows how this does not always work.
Department 110 manager: USING manager_id gives wrong answer
DEPARTMENT_NAME LAST_NAME FIRST_NAME MANAGER_ID ------------------------------ ------------------------- -------------------- ---------- Accounting Gietz William 205 1 SELECT department_name, last_name, first_name, manager_id 2 FROM departments dep 3 JOIN employees USING (manager_id) 4* WHERE dep.department_id = 110
From the first query above we know that the manager of department 110 is Shelley Higgins. It’s reported here instead as William Gietz, because his manager is the same as the department’s manager, but Shirley’s is not.
Department 110 manager: ON mgr.employee_id = dep.manager_id gives right answer
DEPARTMENT_NAME LAST_NAME FIRST_NAME ------------------------------ ------------------------- -------------------- Accounting Higgins Shelley 1 SELECT department_name, last_name, first_name 2 FROM departments dep 3 JOIN employees mgr ON mgr.employee_id = dep.manager_id 4* WHERE dep.department_id = 110
Here we we specify the join with the ON-clause linking the columns explicitly on each side of the join. This is the most usual approach to ANSI joins.
Department 110 manager: NATURAL JOIN subqueries
In a recent article (A tribute to Natural Join, 20 August 2018) Frank Pachot suggested that NATURAL JOIN could be more widely used if tables were replaced by subqueries in which all the columns were aliased in such a way that the join columns only would have the same names in the joined tables. The query above, implemented in this way might be written:
DEPARTMENT_NAME MGR_LAST_NAME MGR_FIRST_NAME ------------------------------ ------------------------- -------------------- Accounting Higgins Shelley 1 SELECT department_name, mgr_last_name, mgr_first_name 2 FROM 3 (SELECT department_id, department_name, manager_id 4 FROM departments) dep 5 NATURAL JOIN 6 (SELECT employee_id manager_id, last_name mgr_last_name, first_name mgr_first_name 7 FROM employees) mgr 8* WHERE dep.department_id = 110
This version is much more verbose and it’s much harder to see which are the join columns by scanning the select lists, compared with specifying them in ON clauses.
Conclusions on Joins via NATURAL/USING/ON
- Very few people use NATURAL JOIN due to the limitation that the join column names, and only those, in each table or subquery have to be the same
- USING tends to be used in simple ad hoc queries with small numbers of tables, and improves on NATURAL JOIN by listing the join columns explicitly, but again relies on the join column names being the same
- The most commonly used join mechanism is the ON clause, with column names specified on each side. This avoids the possible pitfalls of the other mechanisms and for complex, real world queries generally results in more maintainable code
Regarding the DRY principle in SQL more generally, I wrote this,
Modularity in SQL: Patterns, Anti-Patterns and the Kitchen Sink, in September 2013 [tl;dr: Functions and complex views are fine as entry-points but using them as building blocks in SQL is usually a bad idea, and subquery factors (WITH clause) are a better approach to SQL modularity].
Part III: On Data Models and Queries Viewed as Networks
In the examples above we saw that when there are two ways of joining a pair of tables it’s no longer possible for the data model alone to determine the join. An entity relationship structure can be represented as a directed network, with entities as nodes and the relationships between them as links. The second example corresponds to a loop in the network, in which there are two ways of getting from the driving node, departments, to the employees node.

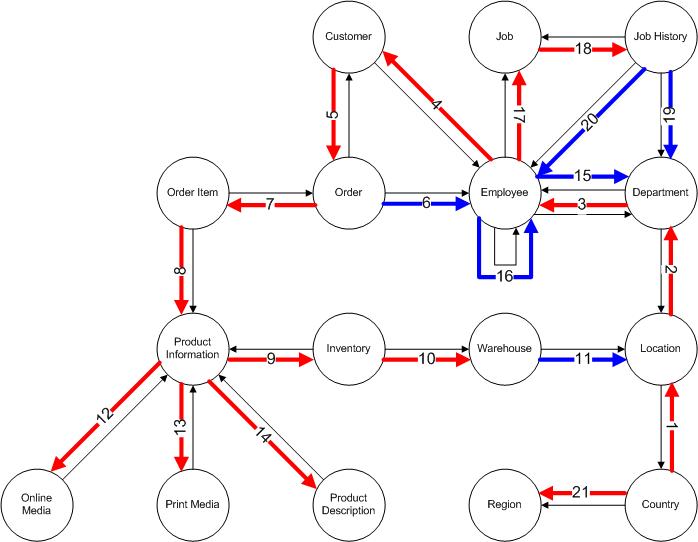
Where the relationships between tables are stored in constraints metadata we can use network analysis PL/SQL to show the network structure and then make diagrams to help in understanding schema structures, as I showed here in May 2015:
PL/SQL Pipelined Function for Network Analysis. This diagram, extracted from that article, shows the structure of Oracle’s demo schemas, with what’s known in graph theory as a spanning tree marked in red, and loop-closing links in blue.
Queries as Networks
In 2009 I was asked to extend the functionality of an Oracle ERP invoice print report in order to support a move to a multi-org ERP structure. The report had a large number (I think around 30) of small queries in various places, such as format triggers and formula columns as well as in the main data model, and I started by combining most of them into a single, fairly complex query plus one smaller, global data query. The report ran much more quickly and I felt was more maintainable since almost all the logic was in one place, and the query could be tested through tools such as Toad. However, as the query was quite complex I was asked to produce some documentation on how it worked. This got me thinking about how ERDs are used to document data models, and whether we could extend those ideas to document queries too.
My initial thought was that a query can be thought of as a route through the data model network, with looping corresponding to repeated table instances in the query. However, it turns out to be much clearer to represent each table instance as its own node on a new network diagram. After I left the company I wrote my ideas up in a general form in a word document on Scribd in May 2009, A Structured Approach to SQL Query Design. Since then I have extended these ideas to include coverage of query constructs such as unions and subquery factors, and use of annotations for clarity. I wrote another article in August 2012 where I apply these extended ideas to some example queries taken from the OTN forum, Query Structure Diagramming. Here’s a diagram from that article:

You can also find examples in several of the articles on combinatorial SQL referenced in Knapsacks and Networks in SQL from December 2017.
How many tables is too many?
Have you ever heard the view expressed, usually by a DBA, that you should not put more than a small number of tables, say 10, in any query? The reasoning given is that the number of join orders for N tables is N!, which for N=10 is 3,628,800 and the query optimiser (CBO) won’t be able to handle that number of permutations. You will probably know from the discussion above why this reasoning is incorrect: The cost optimization problem is really a network path problem, rather than a permutation problem – you look to join (large) tables that are linked to the current rowset rather than than making cartesian joins, so most permutations are never considered.






