
[This article was migrated to the author’s GitHub Pages site here in July 2025]
Oracle eBusiness applications allow audit history records to be automatically maintained on database tables, as explained in the release 12 System Administrator’s guide, Reporting On AuditTrail Data.
Oracle E-Business Suite provides an auditing mechanism based on Oracle database triggers. AuditTrail stores change information in a “shadow table” of the audited table. This mechanism saves audit data in an uncompressed but “sparse” format, and you enable auditing for particular tables and groups of tables (“audit groups”).
Oracle provides an Audit Query Navigator page where it is possible to search for changes by primary key values. For reporting purposes, the manual says:
You should write audit reports as needed. Audit Trail provides the views of your shadow tables to make audit reporting easier; you can write your reports to use these views.
In fact the views are of little practical use, and it is quite hard to develop reports that are user-friendly, efficient and not over-complex, owing, amongst other things, to the “sparse” data format. However, once you have developed one you can use that as a design pattern and starting point for audit reporting on any of the eBusiness tables.
In this article I provide such a report for auditing external bank account changes on Oracle eBusiness 12.1. The report displays the current record, with lookup information, followed by a list of the changes within an input date range. Only records that have changes within that range are included, and for each change only the fields that were changed are listed. The lookup information includes a list of detail records, making the report overall pretty general in structure: It has a master entity with two independent detail entities, and therefore requires a minimum of two queries. This minimum number of queries is usually the best choice and is what I have implemented (it’s fine to have an extra query for global data, but I don’t have any here). The main query makes extensive use of analytic functions, case expressions and subquery factors to achieve the necessary data transformations as simply and efficiently as possible.
The report is implemented in XML (or BI) Publisher, which is the main batch reporting tool for Oracle eBusiness.
I start by showing sample output from the report, followed by the RTF template. The queries are then documented, starting with query structure diagrams with annotations explaining the logic. A link is included to a zip file with all the code and templates needed to install the report. Oracle provides extensive documentation on the setup of Auditing and developing in XML Publisher, so I will not cover this.
Report Layout
Example Output in Excel Format
- There are three regions
- Bank Account Current Record – the master record
- Owners – first detail block, listing the owners of the bank account
- Bank Account Changes – the second detail block, listing the audit history. Note that unchanged fields are omitted
- Note that some audit fields are displayed directly, such as account number, while for others, such as branch number, the display value is on a referenced table
XML Publisher RTF Tempate
- Note that each audit field has its own row in the table, but the if-block excludes it if both old and new values are null
Audit Query
Query Structure Diagram
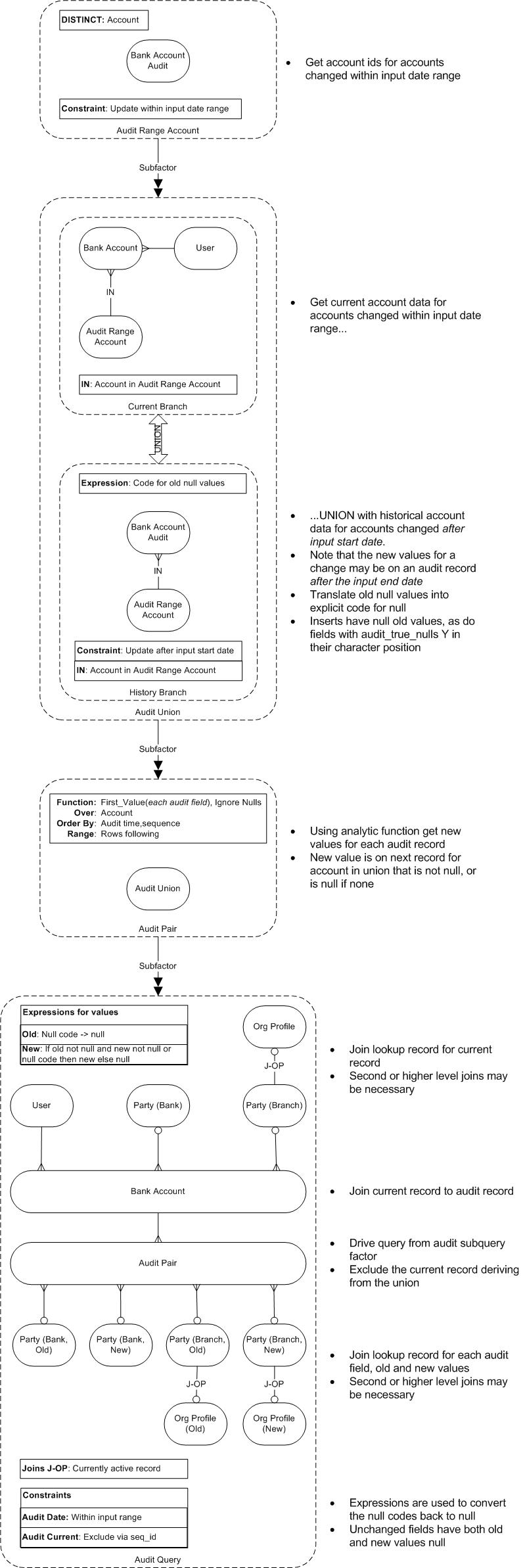
Subquery Tabulation
SQL
WITH audit_range AS (
SELECT DISTINCT ext_bank_account_id
FROM iby_ext_bank_accounts_a aup
WHERE 1=1
&lp_beg_dat
&lp_end_dat
), audit_union AS (
SELECT ext_bank_account_id acc_id,
CASE WHEN Substr (audit_true_nulls, 2, 1) = 'Y' OR audit_transaction_type = 'I' THEN '*NULL*' ELSE bank_account_name END acc_name,
CASE WHEN Substr (audit_true_nulls, 3, 1) = 'Y' OR audit_transaction_type = 'I' THEN '*NULL*' ELSE bank_account_num END acc_num,
CASE WHEN Substr (audit_true_nulls, 8, 1) = 'Y' OR audit_transaction_type = 'I' THEN '*NULL*' ELSE iban END iban,
CASE WHEN Substr (audit_true_nulls, 7, 1) = 'Y' OR audit_transaction_type = 'I' THEN '*NULL*' ELSE currency_code END curr,
CASE WHEN Substr (audit_true_nulls, 6, 1) = 'Y' OR audit_transaction_type = 'I' THEN '*NULL*' ELSE country_code END coun,
CASE WHEN Substr (audit_true_nulls, 4, 1) = 'Y' OR audit_transaction_type = 'I' THEN 0 ELSE bank_id END bank_id,
CASE WHEN Substr (audit_true_nulls, 5, 1) = 'Y' OR audit_transaction_type = 'I' THEN 0 ELSE branch_id END branch_id,
audit_sequence_id seq_id,
audit_timestamp,
audit_user_name a_user,
CASE WHEN audit_transaction_type = 'I' THEN 'INSERT' ELSE 'UPDATE' END a_type
FROM iby_ext_bank_accounts_a aup
WHERE aup.ext_bank_account_id IN (SELECT ext_bank_account_id FROM audit_range)
&lp_beg_dat
UNION
SELECT bac.ext_bank_account_id,
bac.bank_account_name,
bac.bank_account_num,
bac.iban,
bac.currency_code,
bac.country_code,
bac.bank_id,
bac.branch_id,
NULL,
bac.last_update_date,
usr.user_name,
NULL
FROM iby_ext_bank_accounts bac
JOIN fnd_user usr
ON usr.user_id = bac.last_updated_by
WHERE bac.ext_bank_account_id IN (SELECT ext_bank_account_id FROM audit_range)
), audit_pairs AS (
SELECT acc_id,
acc_name,
bank_id,
First_Value (bank_id IGNORE NULLS) OVER
(PARTITION BY acc_id ORDER BY audit_timestamp, seq_id ROWS BETWEEN 1 FOLLOWING AND UNBOUNDED FOLLOWING) bank_id_n,
branch_id,
First_Value (branch_id IGNORE NULLS) OVER
(PARTITION BY acc_id ORDER BY audit_timestamp, seq_id ROWS BETWEEN 1 FOLLOWING AND UNBOUNDED FOLLOWING) branch_id_n,
First_Value (acc_name IGNORE NULLS) OVER
(PARTITION BY acc_id ORDER BY audit_timestamp, seq_id ROWS BETWEEN 1 FOLLOWING AND UNBOUNDED FOLLOWING) acc_name_n,
acc_num,
First_Value (acc_num IGNORE NULLS) OVER
(PARTITION BY acc_id ORDER BY audit_timestamp, seq_id ROWS BETWEEN 1 FOLLOWING AND UNBOUNDED FOLLOWING) acc_num_n,
iban,
First_Value (iban IGNORE NULLS) OVER
(PARTITION BY acc_id ORDER BY audit_timestamp, seq_id ROWS BETWEEN 1 FOLLOWING AND UNBOUNDED FOLLOWING) iban_n,
curr,
First_Value (curr IGNORE NULLS) OVER
(PARTITION BY acc_id ORDER BY audit_timestamp, seq_id ROWS BETWEEN 1 FOLLOWING AND UNBOUNDED FOLLOWING) curr_n,
coun,
First_Value (iban IGNORE NULLS) OVER
(PARTITION BY acc_id ORDER BY audit_timestamp, seq_id ROWS BETWEEN 1 FOLLOWING AND UNBOUNDED FOLLOWING) coun_n,
seq_id,
audit_timestamp,
a_user,
a_type
FROM audit_union
)
SELECT aup.acc_id,
par_bnk.party_name bank_name,
par_brn.party_name bra_name,
orp.bank_or_branch_number bra_num,
bac.bank_account_name acc_name,
bac.bank_account_num acc_num,
bac.iban,
bac.country_code coun,
bac.currency_code curr,
To_Char (bac.creation_date, 'DD-MON-YYYY HH24:MI:SS') creation_date,
usr.user_name created_by,
To_Char (aup.audit_timestamp, 'DD-MON-YYYY HH24:MI:SS') a_time,
aup.a_user,
aup.a_type,
/*
attr: 1. NULL -> no change; 2. 0/'*NULL*' -> change from null; 3. 'other'-> change from not null
old: 1 and 2 both return NULL; 3 returns old not null value
new: only return value for 2 and 3, meaning some change
*/
CASE WHEN aup.bank_id != 0 THEN par_bnk_o.party_name END bank_name_o,
CASE WHEN aup.bank_id IS NOT NULL THEN CASE WHEN aup.bank_id_n != 0 THEN par_bnk_o.party_name END END bank_name_n,
CASE WHEN aup.branch_id != 0 THEN par_brn_o.party_name END bra_name_o,
CASE WHEN aup.branch_id IS NOT NULL THEN CASE WHEN aup.branch_id_n != 0 THEN par_brn_n.party_name END END bra_name_n,
CASE WHEN aup.branch_id != 0 THEN orp_o.bank_or_branch_number END bra_num_o,
CASE WHEN aup.branch_id IS NOT NULL THEN CASE WHEN aup.branch_id_n != 0 THEN orp_n.bank_or_branch_number END END bra_num_n,
CASE WHEN aup.acc_name != '*NULL*' THEN aup.acc_name END acc_name_o,
CASE WHEN aup.acc_name IS NOT NULL THEN CASE WHEN aup.acc_name_n != '*NULL*' THEN aup.acc_name_n END END acc_name_n,
CASE WHEN aup.acc_num != '*NULL*' THEN aup.acc_num END acc_num_o,
CASE WHEN aup.acc_num IS NOT NULL THEN CASE WHEN aup.acc_num_n != '*NULL*' THEN aup.acc_num_n END END acc_num_n,
CASE WHEN aup.iban != '*NULL*' THEN aup.iban END iban_o,
CASE WHEN aup.iban IS NOT NULL THEN CASE WHEN aup.iban_n != '*NULL*' THEN aup.iban_n END END iban_n,
CASE WHEN aup.curr != '*NULL*' THEN aup.curr END curr_o,
CASE WHEN aup.curr IS NOT NULL THEN CASE WHEN aup.curr_n != '*NULL*' THEN aup.curr_n END END curr_n,
CASE WHEN aup.coun != '*NULL*' THEN aup.coun END coun_o,
CASE WHEN aup.coun IS NOT NULL THEN CASE WHEN aup.coun_n != '*NULL*' THEN aup.coun_n END END coun_n
FROM audit_pairs aup
JOIN iby_ext_bank_accounts bac
ON bac.ext_bank_account_id = aup.acc_id
LEFT JOIN hz_parties par_bnk
ON par_bnk.party_id = bac.bank_id
LEFT JOIN hz_parties par_bnk_o
ON par_bnk_o.party_id = aup.bank_id
LEFT JOIN hz_parties par_bnk_n
ON par_bnk_n.party_id = aup.bank_id_n
LEFT JOIN hz_parties par_brn
ON par_brn.party_id = bac.branch_id
LEFT JOIN hz_organization_profiles orp
ON orp.party_id = par_brn.party_id
AND SYSDATE BETWEEN Trunc (orp.effective_start_date) AND Nvl (Trunc (orp.effective_end_date), SYSDATE+1)
LEFT JOIN hz_parties par_brn_o
ON par_brn_o.party_id = aup.branch_id
LEFT JOIN hz_organization_profiles orp_o
ON orp_o.party_id = par_brn_o.party_id
AND SYSDATE BETWEEN Trunc (orp_o.effective_start_date) AND Nvl (Trunc (orp_o.effective_end_date), SYSDATE+1)
LEFT JOIN hz_parties par_brn_n
ON par_brn_n.party_id = aup.branch_id_n
LEFT JOIN hz_organization_profiles orp_n
ON orp_n.party_id = par_brn_n.party_id
AND SYSDATE BETWEEN Trunc (orp_n.effective_start_date) AND Nvl (Trunc (orp_n.effective_end_date), SYSDATE+1)
JOIN fnd_user usr
ON usr.user_id = bac.created_by
WHERE aup.seq_id IS NOT NULL
&lp_beg_dat
&lp_end_dat
ORDER BY aup.acc_id, aup.audit_timestamp DESC, aup.seq_id DESC
Owners Query
Query Structure Diagram

Subquery Tabulation
SQL
SELECT par.party_name owner,
sup.vendor_name,
sup.segment1
FROM iby_account_owners own
JOIN hz_parties par
ON par.party_id = own.account_owner_party_id
LEFT JOIN ap_suppliers sup
ON sup.party_id = par.party_id
WHERE own.ext_bank_account_id = :ACC_ID
Code for Bank Account Auditing XML Publisher Report
See also A Generic Unix Script for Uploading Oracle eBusiness Concurrent Programs